Date
Description
Image

Photo courtesy of U.S. Department of Agriculture
A downloadable version of this explainer is available here:
Document
Overview
Previous explainers have introduced the topics of narrative and visual discourse analysis, which socio-environmental (S-E) researchers may use to identify the rhetorical impacts of images and text within a particular social context. Qualitative content analysis1 (QCA) is an extension of narrative analysis that integrates specialized software. QCA blends qualitative and quantitative methods to organize a large number of texts into a standardized system of thematic coding, which can reveal discursive bias and cultural or organizational trends. QCA may reveal historical, geographical, and demographic patterns, as well as the ways in which archival documents may represent and preserve existing power structures and the priorities of managers invested in the status quo. By coding for categories that focus on trade-offs (for example, categorical choices among economic, social justice, and hydrological priorities), QCA can show commonalities among a wide range of texts, including links between disparate sectors, strategies used by various actors, and the regulations governing activities in socio-environmental systems.
QCA researchers often begin with quantitative methods, such as software that allows them to analyze the number of times a keyword is used in a text. Software-enabled QCA allows researchers to amplify narrative analysis by generating codes that represent a large number of specific keywords, which aid researchers in grouping the textual content into themes, categories, and subcategories. By coding keywords and themes, researchers may reveal both coding frequency (number of keyword hits), and relative thematic distribution across publications with particular topical and regional foci. The goal is to find a range of terms with similar meanings that are expressed in different ways in various media forms. Researchers decide how to code their target papers based on qualitative choices of which themes interest them and what types of sentiments they believe could be reflected in the texts.
Burke et al. (2015) showed how a team of three authors can conduct a simple qualitative analysis of theme, content, and tone within a single periodical to reveal how competing environmental discourses affect public knowledge and create or diffuse a collective desire to act toward conservation. They conducted a narrative and keyword analysis of the environmental columns of an influential regional newspaper in southern Appalachia to explore how the journalists discursively construct the environment, its interrelation with human activities, and currently favored forms of environmental governance. The authors read a large store of recent issues and agreed-upon keyword codes that indicated the content that covered target themes, including environment, science, and policy or governance. They identified 53 relevant coded segments that reveal the articles’ thematic content, which they cross-analyzed using a series of variables: the articles’ overall goal; emotional tone; people depicted; spatial and temporal scales; inclusion of environmental politics and value systems; the representation of risk; and change in the environment (such as suburbanization) or governance (forms of regulation).
Image

The values revealed by this QCA showed the newspaper’s dominant discourse of showcasing passive pleasure within the acculturated environment (including golf courses and gardens) rather than observing problems or suggesting active interventions to preserve natural resources. This choice of an “outdoor life” discourse with limited human agency notably departs from more activist or conservationist discourse that would attune the regional conversation to ongoing stressors like suburbanization, climate change, and inequality.
Burke et al. noted how this discursive tone aligns with a local culture of uncontroversial politeness, but the content does not represent the diversity of view nor the fundamental changes in land use and demographics that endanger many aspects of the Appalachian ecosystem. Their approach exemplifies how a small team may analyze the social implications of environmental content in a comprehensive way by limiting themselves to one target publication and using themes to cut through content and reveal the cultural values that the discourse supports. This simple reader-review approach is most effective when focusing on the characteristics of a regional discourse and a limited stock of texts (one newspaper) rather than a cross-comparison that traverses regions, document types, and the views of different disciplines or stakeholders. This SESYNC lesson guides learners through a similar discourse analysis exercise.
1 Not to be confused with Qualitative Comparative Analysis (also QCA), which combines quantitative and qualitative information from case studies to model causal conditions that can account for a full range of observed outcomes. See SESYNC’s learning resource that explains this method in detail.
QCA and Big Data
When handling larger or more diverse stores of discourse, a blend of computer-based and reader-review strategies is most effective. Software like Atlas.TI and the R packages allow researchers to upload the full text from high volumes of documents and analyze their content based on themes, coded segments, and variables like geography or document type. This strategy allows researchers to highlight cross-sector themes that may be overlooked by single discipline or single stakeholder analysis, and it may be revised iteratively as new concepts and terms emerge.
For example, Hoover et al. (2021) employed a dataset of 119 planning documents in 19 U.S. cities to examine the siting criteria for Green Infrastructure (GI) projects. The researchers were interested in how environmental justice considerations may or may not influence GI siting across cities. They used an initial keyword search of “green infrastructure” to identify relevant sections in the documents. They standardized further analysis of these hits using spreadsheets that described in narrative the types of siting criteria (environmental justice (EJ), water quality, feasibility, etc.) cross-referenced with document codes that specify the city, document, and thematic code group (hydrologic, social, economic, etc.). They then used Atlas.TI software to apply the descriptive coding regime to the list of general siting criteria codes based on GI planning documents. From this iterative coding process, they visualized 1,805 text segments across 12 siting categories and 35 subcategories (using R program’s “ggpubr” package) to examine the coding frequency and distribution across cities. This step allowed the team to create a series of visuals that illustrated the factors that influence GI siting criteria.
Image
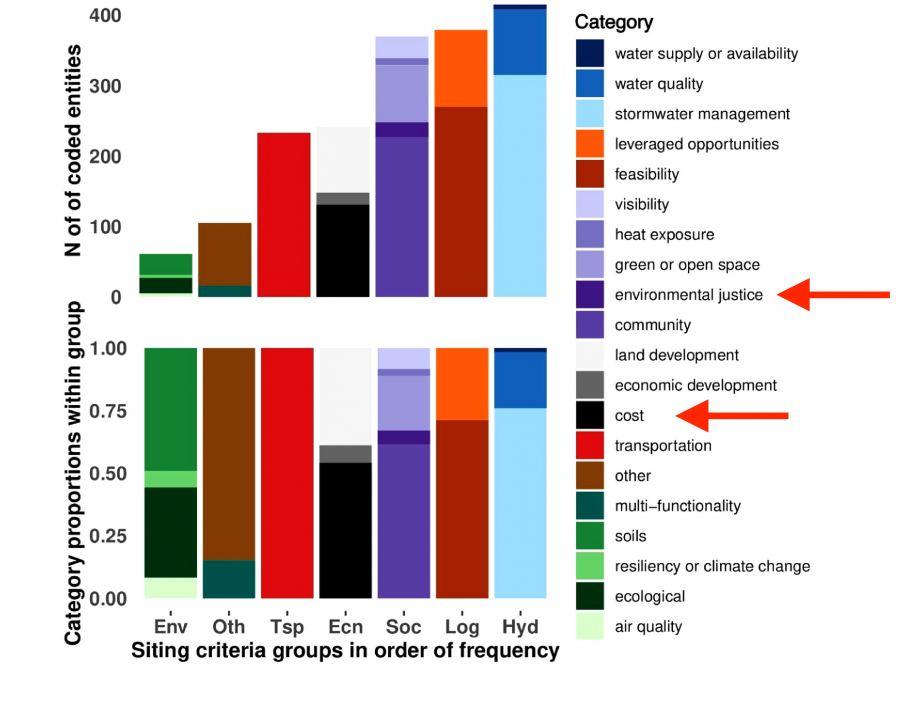
In Figure 3 from Hoover et al. (above), all 19 target cities used cost or economics as siting criteria for GI; 16 used hydrology or stormwater management; and only 7 included environmental justice or equity as criteria for the placement of GI projects. The text “environmental justice” accounted for only 1.2% of coded criteria in the seven cities in which EJ was mentioned at all in planning documents. The authors concluded that the low prevalence of EJ discourse in GI planning documents may cause unjust outcomes that prioritize investing amenities in privileged communities instead of addressing the underlying structural inequalities that give EJ communities less access to environmental benefits. By using this QCA approach, enhanced by software-driven document processing and visuals, the team generated clear and actionable results out of a large, complex discourse sample that cuts across cities, criteria, and categories. They acknowledged a key assumption of the study: the frequency and quality of specific kinds of discourse in planning documents (here, EJ inclusion) reflects actual municipal priorities and future designs for GI siting.
Furthermore, some researchers wish to contextualize official policy or planning documents with candid interviews of people with first-hand experience of S-E systems governance and operation. For example, Lund et al. (2022) used a combined QCA, narrative, and interview-based analysis approach to assess archival documents in the Senegal River Basin’s (SRB) food-energy-water (FEW) nexus with the additional consideration of health (FEW+H). For the QCA, they used deduction to develop a FEW+H nexus-specific coding scheme based on keywords and concepts they expected to encounter in planning documents. They divided excerpts among the five members of the team for coding and edited the scheme iteratively based on revised expectations of keywords and concepts after an initial analysis. Coding categories focused on trade-offs, links between FEW+H sectors, strategies used by different actors, and the regulations governing basin activities. Interviews with environmental health and hydrologic engineering staff supplemented, validated, and contextualized their QCA findings.
Image
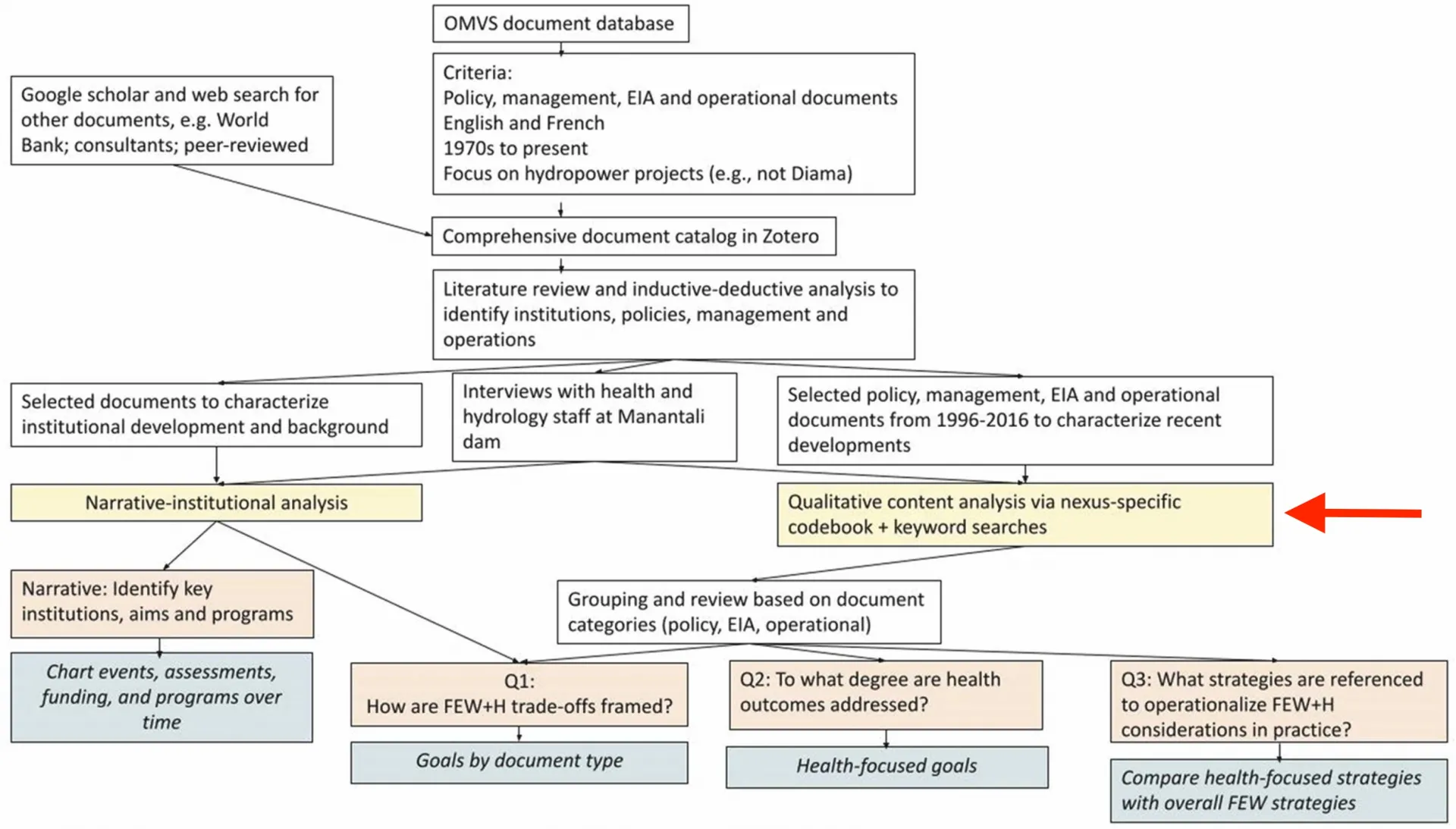
See Figure 2 above from Lund et al. The QCA (indicated by the red arrow added) shows that they identified in the policy and governance documents more goals related to FEW resources than those related to improving socio-economic, environmental, or health measures. Their complementary narrative analysis of policy and governance documents revealed that programs were designed to facilitate the mitigation of health and environmental impacts but they ultimately failed to integrate health into river basin operations. In the documents, heath is discussed as an externality to FEW priorities, and health-related excerpts represented only a small portion of coded data. In the authors’ analysis of archival documents since 1970, they found where in the planning cycle health is overlooked—between dam and reservoir operations and in key areas of decision making, such as impact assessments and basin-wide programs. Note that in their combined approach, the authors’ narrative analysis provided a history of the institution’s aims and programs while the interviews established a gap between official documents and actual operations. Lund et al.’s blended discourse analysis created an understanding of how SRB actors view the health impacts of dams: they are aware of them but fall short of managing them. The authors identify key barriers to achieving integrated sustainable development: 1) the need to generate and synthesize knowledge across sectors and 2) the use of that knowledge as a basis for decision making and implementation. These insights provided critical context for the keyword-and-code-based QCA. Without all forms of analysis, the team would not have been able to situate their findings within particular contexts of the SRB’s regulatory history.
Lund et al. noted that their findings are limited to the quality and accuracy of the documents they analyzed, a point worth considering across these discourse analysis cases. Institutional documents are assumed to reflect the policy-to-practice continuum and discuss priorities accurately, but choices in the moment are not always recorded in official documents. By adding an interview component, the team integrated more candid views of SRB dam operations than may exist in official publications.
QCA is an approachable technique for S-E researchers who possess or wish to develop basic software skills to analyze documents on a large scale. As the QCA approach reduces text to codes and excerpts to take on big archives, other forms of discourse analysis like narrative analysis and interviews may complement the QCA and provide a more textured and contextual view of the range of perspectives on an S-E issue.
References
Burke, B.J., Welch-Divine, M., & Gustafson, S. (2015). Nature Talk in an Appalachian Newspaper: What Environmental Discourse Analysis Reveals about Efforts to Address Exurbanization and Climate Change. Human Organization, 74( 2), 185- 196. http://doi.org/10.17730/0018-7259-74.2.185
Hoover, F.A., Meerow, S., Grabowski, Z.J. et al. (2021). Environmental justice implications of siting criteria in urban green infrastructure planning. Journal of Environmental Policy & Planning, 23(5), 665-682. https://doi.org/10.1080/1523908X.2021.1945916
Lund, A.J., Harrington, E., Albrecht, T.R. (2022). Tracing the inclusion of health as a component of the food-energy-water nexus in dam management in the Senegal River Basin. Environmental Science and Policy,133, 74–86. https://doi.org/10.1016/j.envsci.2022.03.005
Share